2015 Timesaving Comprehensive Guides For Microsoft 70-448 Exam: Using Latst Released Braindump2go 70-448 Practice Tests Questions, Quickly Pass 70-448 Exam 100%! Following Questions and Answers are all the New Published By Microsoft Official Exam Center!
Exam Code: 70-448
Exam Name: Microsoft SQL Server 2008, Business Intelligence Development and Maintenance
Certification Provider: Microsoft
Corresponding Certifications: MCITP: Business Intelligence Developer 2008, MCSA, MCSA: SQL Server 2008, MCTS, MCTS: Microsoft SQL Server 2008, Business Intelligence Development and Maintenance
Keywords: 70-448 Exam Dumps,70-448 Practice Tests,70-448 Practice Exams,70-448 Exam Questions,70-448 PDF,70-448 VCE Free,70-448 Book,70-448 E-Book,70-448 Study Guide,70-448 Braindump,70-448 Prep Guide
QUESTION 141
You are a database developer and you have about two years experience in creating business intelligence (BI) solutions by using SQL Server 2008.
Now you are employed in a company which is named NaproStar and work as the technical support for the company which uses SQL Server 2008.
To meet the business development’a SQL Server 2008 Analysis Services (SSAS) solution is created.
Then a dimension named DimClient is created with the three attributes of Client, Age and Name.
Of the three attributes, the Client is the key.
There is a measure group named Production with the Granularity property set to Age and DimClient is related to this group.
Now you receive an e-mail from your company CIO, according to his requirement, you should make sure that measure values can be retrieved based on the Age and Name attributes.
To achieve this goal, what action should you perform?
A. First the source attribute should be set to Age and the related attribute should be set to Client, and
then the source attribute should be set to Name and the related attribute should be set to Client
B. First the source attribute should be set to Name and the related attribute should be set to Client, and
then the source attribute should be set to Age and the related attribute should be set to Client
C. First the source attribute should be set to Client and the related attribute should be set to Age, and
then the source attribute should be set to Age and the related attribute should be set to Name.
D. First the source attribute should be set to Age and the related attribute should be set to Client, and
then the source attribute should be set to Name and the related attribute should be set to Age
E. First the source attribute should be set to Client and the related attribute should be set to Age, and
then the source attribute should be set to Client and the related attribute should be set to Name
Answer: C
Explanation:
To create a new attribute relationship, follow these steps:
1. In the Attributes pane, right-click the source attribute that is on the “one” side of the relationship, and then select New Attribute Relationship.
2. Configure the relationship by using the Create Attribute Relationship dialog box
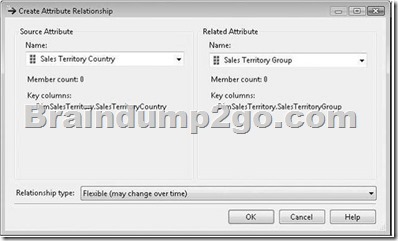
Make sure that the Name drop-down list below Source Attribute shows the attribute that is on the “many” side of the relationship and that the Name drop-down list below Related Attribute shows the attribute on the “one” side of the relationship. Use the Relationship Type drop-down list to specify a Flexible or Rigid relationship type. You can also create a new relationship in the Dimension Designer by dragging the source attribute onto the related attribute in the Diagram pane.
To delete an attribute relationship, select the relationship in the Attribute Relationships pane (or click the arrow connector in the Diagram pane) and then press Delete,
QUESTION 142
You are a database developer and you have about two years experience in creating business intelligence (BI) solutions by using SQL Server 2008.
Now you are employed in a company which is named NaproStar and work as the technical support for the company which uses SQL Server 2008.
2008 Analysis Services (SSAS) solution is created.
You also create a dimension named DimCustomer.
Following is the cube structure: (Click the Exhibit button.)
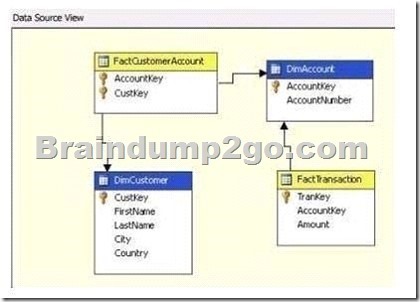
Now you get an order from your company CIO, according to his requirement, you should make sure that you can aggregate the Amount measure for the DimCustomer dimension.
What action should you perform to achieve that goal?
A. A many-to-many relationship should be created between FactTransaction and DimCustomer.
Besides, FactCustomerAccount should be set as an intermediate measure group.
B. A many-to-many relationship should be created between FactCustomerAccount and DimCustomer.
Besides, FactTransaction should be set as an intermediate measure group
C. A regular relationship should be created between FactCustomerAccount and DimCustomer.
Besides, FactTransaction should be set as an intermediate measure group
D. A regular relationship should be created between FactTransaction and DimCustomer
E. A referenced relationship should be created between FactCustomerAccount and DimCustomer.
Besides, DimAccount should be set as an intermediate dimension.
Answer: A
QUESTION 143
You are a database developer and you have about two years experience in creating business intelligence (BI) solutions by using SQL Server 2008.
Now you are employed in a company which is named NaproStar and work as the technical support for the company which uses SQL Server 2008 Analysis Services (SSAS) solution.
You have a table named Bills with three columns contained.
They are respectively Shipper, BillKey and BillQuantity.
To meet the business development, a dimension named DimBills and a measure group named TruthBills are created from the Bills table.
Besides, the BillKey is set as a key column and the Shipper is set as an attribute column.
According to the order of the CIO, a dimension relationship between the BillQuantity column and the Shipper column should be created to make sure that the Shipper column is able to aggregate BillQuantity column.
What action below should be performed to achieve this goal?
A. A regular dimension relationship should be created between the DimBills dimension and the TruthBills
measure group.
B. The relationship between the TruthBills measure group and DimBills dimension should be set to No
Relationship.
C. A Truth dimension relationship should be created between the TruthBills measure group and DimBills
dimension
D. A regular dimension relationship should be created between the DimBills dimension and the TruthBills
measure group.
Besides, the Granularity attribute to Shipper and the measure group columns should be set to BillQuantity.
E. A regular dimension relationship should be created between the DimBills dimension and the TruthBills
measure group.
Besides, the Granularity attribute to BillKey and the measure group columns should be set to BillQuantity
Answer: C
QUESTION 144
You are a database developer and you have about two years experience in creating business intelligence (BI) solutions by using SQL Server 2008.
Now you are employed in a company which is named NaproStar and work as the technical support for the company which uses SQL Server 2008 Analysis Services (SSAS).
To meet the business development, you create a (SSAS) solution and enable proactive caching for a partition. Now you get an order from your company CIO, according to his requirement, while updating the multidimensional storage, you should make sure that you can use SSAS to query relational data.
What action below should be performed?
A. To achieve this goal, the OnlineMode property for the partition should be set to OnCacheComplete
B. To achieve this goal, the ProcessingMode property for the partition should be set to LazyAggregations.
C. To achieve this goal, the OnlineMode property for the partition should be set to Immediate.
D. To achieve this goal, the ProcessingMode property for the partition should be set to Regular
Answer: C
Explanation:
ProcessingMode
Defines the place in the cube processing at which data becomes available to users. By default,
ProcessingMode is set to Regular, and users cannot access the measure group until processing is complete. If ProcessingMode is set to LazyAggregations, data is accessible as soon as it is processed, but processing takes longer.
QUESTION 145
You are a database developer and you have about two years experience in creating business intelligence (BI) solutions by using SQL Server 2008.
Now you are employed in a company which is named NaproStar and work as the technical support for the company which uses SQL Server 2008.
To meet the business development, you create a SQL Server 2008 Analysis Services (SSAS) solution, which has a hierarchy named Season in a Time dimension named Dimtime.
The attributes of Spring level, Summer level, Autumn level and Winter level are contained in the Season hierarchy.
Now you are assigned a task to create a named set to refer to the first season of the year 2008.
What action should you perform to accomplish this task?
A. You should write ParallelPeriod([DimTime]. [Spr-Sum-Aut].[Spr], 1, [DimTime].
[Spr- Sum-Aut].[Aut].[ Spring 2008]) for the named set.
B. You should write ParallelPeriod ([DimTime]. [Spr-Sum-Aut].[Aut], 1, [DimTime].
[Spr- Sum-Aut].[Aut].[ Spring 2008]) for the named set
C. You should write PeriodsToTime([DimTime].[Spr-Sum-Aut].[Spr], [DimTime].
[Spr-Sum Aut].[Aut].[Spring 2008]) for the named set
D. You should write PeriodsToTime([DimTime].[Spr-Sum-Aut].[Aut], [DimTime].
[Spr-Sum- Aut].[Aut].[Spring 2008]) for the named set.
Answer: C
Explanation:
http://msdn.microsoft.com/en-us/library/ms144925.aspx
PeriodsToDate (MDX) SQL Server 2008 R2 Other Versions
Returns a set of sibling members from the same level as a given member, starting with the first sibling and ending with the given member, as constrained by a specified level in the Time dimension.
Syntax PeriodsToDate( [ Level_Expression [ ,Member_Expression ] ] ) Arguments Level_Expression – A valid Multidimensional Expressions (MDX) expression that returns a level.
Member_Expression – A valid Multidimensional Expressions (MDX) expression that returns a member.
Remarks
Within the scope of the specified level, the PeriodsToDate function returns the set of periods on the same level as the specified member, starting with the first period and ending with specified member.
* If a level is specified, the current member of the hierarchy is inferred hierarchy.CurrentMember, where hierarchyis the hierarchy of the specified level.
* If neither a level nor a member is specified, the level is the parent level of the current member of the first hierarchy on the first dimension of type Time in the measure group. PeriodsToDate( Level_Expression, Member_Expression ) is functionally equivalent to the following MDX expression:
TopCount(Descendants(Ancestor(Member_Expression, Level_Expression), Member_Expression.Level), 1):
Member_Expression
QUESTION 146
You are a database developer and you have about two years experience in creating business Intelligence (BI) by using SQL Server 2008.
Now you are employed in a companynamed NaproStar which uses SQL Server 2008.
You work as the technical support. Now you are in charge of a SQL Server 2008 Analysis Services (SSAS) database.
A Product dimension is contained in the database.
The dimension contains two attributes both of which have a Rigid relationship type.
The two attributes are the Category attribute and Subcategory attribute.
The relationship between the Category and Subcategory values is changed by the data source for the Product dimension.
Now in order to make the dimension successfully reflect the change, you have to execute an XML for Analysis (XMLA) command to process the dimension to perform this.
What action should you perform?
A. In order to achieve this goal, the ProcessIndexes command should be used
B. In order to achieve this goal, the ProcessAdd command should be used
C. In order to achieve this goal, the ProcessClear and the ProcessDefault commands should be used.
D. In order to achieve this goal, the ProcessUpdate command should be used
Answer: C
Explanation:
ProcessFull ProcessFull applies to all objects. It discards the storage contents of the object and and rebuilds them. ProcessFull is recursively applied to all descendants of the object as well.
ProcessClear ProcessClear applies to all objects. It discards the storage contents of the object.
ProcessClear is recursively applied to all descendants of the object as well. ProcessDefault ProcessDefault applies to all objects. It does the bare minimum required to bring the object to a fully processed state. In other words, it builds only the storage contents that are not currently built. For example, if a partition has fact and aggregation data, then ProcessDefault will only build the bitmap indexes.
The only exception to the above rule is bindings. When you change the bindings of an object (e.g., KeyColumns of a dimension attribute), the object retains its data, but remembers that the bindings have changed. ProcessDefault on the object will discard all the storage contents and rebuild them.
The server handles ProcessDefault by analyzing the object and dynamically converting it to another processing option such as ProcessFull, ProcessIndexes, etc. ProcessDefault is recursively applied to all descendants of the object as well.
ProcessData applies only to the OLAP objects, i.e. dimension, cube, measure group and partition. It discards the storage contents of the object and rebuilds only the “data”. For dimensions, it builds only the attribute and hierarchy stores. For partitions, it builds only the fact data.
Essentially ProcessData builds the bare minimum required for the object to be available for queries. Indexes are considered optional and affect only the query performance. ProcessData is recursively applied to all descendants of the object as well.
ProcessIndexes applies only to the OLAP objects, i.e., dimension, cube, measure group, and partition. It requires that the object must already have its “data” built; otherwise, it raises an error. ProcessIndexes preserves the data and rebuilds the “indexes”. For dimensions, it builds the bitmap indexes. For partitions, it builds the aggregation data and bitmap indexes. ProcessIndexes is recursively applied to all descendants of the object as well.
ProcessUpdate applies only to dimensions. It is the equivalent of incremental dimension processing in Analysis Services 2000. It sends SQL queries to read the entire dimension table and applies the changes– member updates, additions, deletions. Since ProcessUpdate reads the entire dimension table, it begs the question, “How is it different from ProcessFull?” The difference is that ProcessUpdate does not discard the dimension storage contents. It applies the changes in a “smart” manner that preserves the fact data in dependent partitions. ProcessFull, on the other hand, does an implicit ProcessClear on all dependent partitions. ProcessUpdate is inherently slower than ProcessFull since it is doing additional work to apply the changes.
Depending on the nature of the changes in the dimension table, ProcessUpdate can affect dependent partitions. If only new members were added, then the partitions are not affected. But if members were deleted or if member relationships changed (e.g., a Customer moved from Redmond to Seattle), then some of the aggregation data and bitmap indexes on the partitions are dropped. The cube is still available for queries, albeit with lower performance. ProcessAdd applies only to dimensions and partitions.
ProcessAdd is a new processing option for dimensions that did not exist in Analysis Services 2000. It essentially optimizes ProcessUpdate for the scenario where only new members are added. ProcessAdd never deletes or updates existing members. It only adds new members. The user can restrict the dimension table so that ProcessAdd reads only the new rows.
ProcessAdd for partitions is the equivalent of incremental partition processing in Analysis Services 2000. The user typically specifies an alternate fact table or a filter condition pointing to the new rows. ProcessAdd internally creates a temporary partition, processes it with the specified fact data, and merges it into the target partition.
See the Out of Line Bindings section for details on how to specify the new rows for ProcessAdd.
ProcessStructure applies only to cubes and mining structures. ProcessStructure for cubes is the equivalent of the Analysis Services 2000 processing option,
processBuildStructure, in DSO. It discards the storage contents of the cube and its partitions. It implicitly does a ProcessDefault on all dimensions of the cube and marks the cube as processed. At this point, the cube is available to queries but it will not return any fact data. This is supported mostly for backward-compatibility reasons. It was useful in Analysis Services 2000 for parallel processing utilities. Once the “structure” of a cube is processed, its partitions can be processed in parallel by multiple client sessions without running into locking conflicts.
ProcessStructure on a mining structure discards its storage contents (training data) and rebuilds them. It does not affect the contents of the mining models under the mining structure.
ProcessScriptCache ProcessScriptCache applies only to cubes. The MDX script in a cube can contain CACHE statements. ProcessScriptCache evaluates the script and persists the results for the CACHE statements. ProcessClearStructureOnly ProcessClearStructureOnly applies only mining structures. It clears the storage contents (training data) of the mining structure while preserving the contents of its mining models.

QUESTION 147
You are a database developer and you have about two years experience in creating business intelligence (BI) solutions by using SQL Server 2008.
Now you are employed in a company which is named NaproStar and work as the technical support for the company which uses SQL Server 2008 Analysis Services (SSAS) solution.
To meet the business development, a dimension named DimSales is created with an Amount attribute, and then it is used in a cube structure.
Now you are assigned a task to make sure that aggregations have no relationship with the Amount attribute.
What action should you perform to accomplish this task?
A. The MembersWithData property of the Amount attribute should be set to False to accomplish this task.
B. The IsAggregatable property of the Amount attribute should be set to False to accomplish this task.
C. The AttributeHierarchyEnabled property of the Amount attribute should be set to False to accomplish
this task.
D. The MembersWithData property of the Amount attribute should be set to NonLeafDataHidden to
accomplish this task
E. The GroupingBehavior property of the Amount attribute should be set to DiscourageGrouping to
accomplish this task.
Answer: C
QUESTION 148
You are a database developer and you have about two years experience in creating business intelligence (BI) solutions by using SQL Server 2008.
Now you are employed in a company which is named NaproStar and work as the technical support for the company which uses SQL Server 2008.
To meet the business development, you use SQL Server 2008 to create a SQL Server 2008 Integration Services (SSIS) package.
You have a Research server named SQL_RES01 and a Sales server named SQL_SAL01. SQL_RES01 is not connected to SQL_SAL01 in the network.
Then you have the SSIS package configured on the SQL_SAL01 server, however, you get a failure of the configuration, which is because the SQL_RES01 server can not be connected by the package. In order to solve that problem, the package should be modified to refer to the SQL_SAL01 server when you execute the configuration.
Which solution would be chosen to solve that problem?
A. After selecting the Connection Manager check box, you should modify the connection string on the
Connection Managers tab of the Execute Package utility
B. Use the ServerStorage package protection level to modify the properties of the package.
C. After modifying the deployment manifest file in Microsoft Notepad, you should modify the properties
of the package
D. Use the DontSaveSensitive package protection level to modify the properties of the package.
E. After modifying the deployment manifest file in Microsoft Notepad, you should modify the connection
string manually.
Answer: A
QUESTION 149
You are a database developer and you have about two years experience in creating business intelligence (BI) solutions by using SQL Server 2008.
Now you are employed in a company which is named NaproStar and you are in charge of a SQL Server 2008 Integration Services (SSIS) instance.
The SSIS instance has the packages stored in a SQL Server 2008 instance while another SSIS instance had its packages stored in a shared directory.
According to the order of your manager, you need to deploy the package from the SSIS instance to another SSIS instance.
In order to achieve this goal, which command should be executed?
A. The dtexecui command should be executed
B. The dtswiza command should be executed
C. The dtutil command should be executed
D. The Dtexec command should be executed
Answer: C
Explanation:
Manual package deployment You can move your SSIS packages to a destination folder by copying them manually, by using a source-control tool that handles file deployment, or by creating a script or an application that handles the deployment. If you store your package in SQL Server, you can either use the DTUtil command-line utility that comes with SSIS to deploy your packages to SQL Server or manually import them through SSMS.
Using DTExecUI to Configure Package Execution
The command-line executable file DTExec is a fully featured utility with broad parameterization capabilities.
You can generate the command line manually by applying the command parameters to meet the execution circumstance, but to save time and avoid errors, you can use the command-line builder utility named DTExecUI.
DTExecUI is a visual tool that naturally groups the command parameter options. The server on which you run DTExecUI must have SSIS installed. To open DTExecUI, type DTExecUI either from a command prompt or by choosing Start and then Run to open the Run dialog box. You can open the tool from the Run dialog box or from the command prompt without specifying the path.
To use DTExecUI, follow these steps:
1. Open the Execute Package Utility by executing DTExecUI either by choosing Start and then Run, and entering DTE xecUI in the Run dialog box, or through a command prompt.
2. On the General property page, select the package for execution so that you can modify a property on the other pages. In the Package Source drop-down list, select File System, SSIS Package Store, or SQL Server, depending on where your package is located.
3. After identifying the package location, select the specific package for execution. If your package is stored in SQL Server or the SSIS Package Store, you need to specify the connection details to the SQL Server 2008 server by providing the server name. SQL Server also requires you to either provide a user name and password or specify Windows Authentication. All location choices require that you specify the package in the Package box by clicking the ellipsis button to the right of the Package box.
4. Next you need to specify how the package should be executed by configuring other package execution properties. Selecting the various property pages on the left from Configurations down through Verification will let you override settings such as connections, logging, and outputs. Table 4-3 describes the execution configuration options.
QUESTION 150
You are a database developer and you have about two years experience in creating business intelligence (BI) solutions by using SQL Server 2008.
Now you are employed in a company which is named NaproStar and work as a developer of a SQL Server 2008 Integration Services (SSIS) for the company.
To meet the business requirements, SSIS should be used on a SQL Server 2008 failover cluster.
There is a complex package on your server and it needs a long time to start it.
Now your manager asks you to make sure that the package can be resumed when it fails to execute the failover.
What action should you perform?
A. First you should have checkpoints implemented within your package, and then restart the package
whenever a failover occurs
B. First you should have transactions implemented within your package, and then restart the package
whenever a failover occurs.
C. First you should cluster the SSIS service, and then restart the package whenever a failover occurs
D. First you should cluster the SSIS service, and then have the SSIS service added to its own cluster
resource group
E. First you should cluster the SSIS service, and then have the SSIS service added to the SQL Server
cluster resource group.
Answer: A
Explanation:
When you are running a package on a server node of a Windows cluster environment and the node fails, the restartability rules apply. you can turn on checkpoints in your packages and have the checkpoint fi le created on a share so that if the package needs to be restarted, it can locate and use the checkpoint file. Simply put, there are two ways to configure the SSIS service in a clustered environment:
* installing the ssis service independent from the cluster resources
You can install the SSIS components on all nodes of the cluster, and by default, they will not be part of any cluster resource group. The service will be started on all nodes, and you can run packages from any node in the cluster. If all your packages are stored on a network share that is not part of the package store, no further confi guration is needed. If you want to centralize all your packages in SQL Server, you need to change the MsDtsSrvr.ini.xml fi le. Change the < ServerName> element to reference a specific server and instance; if the SQL Server is in the cluster, use the virtual server name and instance. Last, change this fi le on all the nodes so that you can connect to the SSIS service on any machine and see the same packages.
* integrating the ssis service in a cluster group
You can add the SSIS service as a cluster resource, a process detailed in the “Confi guring Integration Services in a Cluster Environment” white paper mentioned earlier. If you want to store packages in the package store, you would choose this approach because the shared service would be running on only one node at a time and you could reference the virtual name of the server. The service would need to point to a shared MsDtsSrvr.ini.xml fi le on a shared drive in the same cluster resource group as the service. This requires a registry change, which is also documented. The package store location also must be on the shared drive in the same cluster resource group.
Braindump2go New Updated 70-448 Exam Dumps are Complete Microsoft 70-448 Course Coverage! 100% Real Questions and Correct Answers Guaranteed! Updated 70-448 Preparation Material with Questions and Answers PDF Instant Download: